
Explain It Like I’m Five: Machine Learning & Kids’ Behavioral Health
My colleague Ali Jaffar sent me this recent article: A machine learning approach for identifying predictors of success in a Medicaid-funded, community-based behavioral health program using the Child and Adolescent Needs and Strengths (CANS). (A bit of a mouthful.) There are some really interesting ideas in here about how to support kids’ success and health from a young age…but it also kind of made me nervous. Take this sentence, for example:
“Our ultimate objective was to create a tool for use by evaluators at intake to identify a client’s probability of success in the program.”
The full picture is important here, but it may be tricky to see it. So in this post, I’m gonna talk you through this article as if I were talking to my soon-to-be kindergartener.
Some kids have problems with their emotions and how they act. When we help them, we should use a big team full of people with different skills. One tool that people use to see what kids need is called the Child and Adolescent Needs and Strengths (CANS). Lots of helpers use this tool. There are millions of new records every year. Because of that, we can see how kids in different programs change. So maybe we can use this data to plan ahead and see what kids are most likely to change?
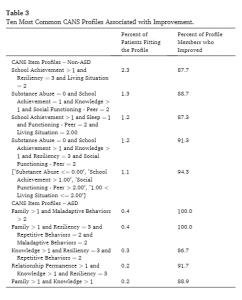
from Troy et al., 2021
By looking at the scores on CANS, the researchers found different types of strengths that were most likely to improve. They had two big categories: kids with ASD (something that happens when kids having trouble communicating and sensing the world), and kids without ASD. I cut and pasted the results here (which, I confess, are above a 5-year).
The researchers also looked at kids who were not in the program. They found a big number of kids would have improved if they had been getting services!
Maybe this type of approach could be used to find kids who are likely to improve and get them into services? The thing is, it could work better if we also consider other things in kids’ lives that impact health. These are called “social determinants of health.”
So, that’s it! This is a pretty cool use of preexisting data, but like I said, it makes me nervous. Here’s why.
For the sake of social justice, I’d want under-served kids to be able to get service to help them improve. This study suggests that there could be a more effective way of identifying them. There is also the added benefit of efficiency because resources are dedicated to those likely to improve.
And yet, it’s also possible that this process (or processes that derive from it) could be used to screen out kids who present ‘tougher’ cases. Then again, if the kids are likely to be more difficult, then this could potentially mean using a different treatment strategy right from the beginning.
Regardless, methods like this one are going to be more common in the near future. It’s critical that we have clear and open dialogue about the strengths and drawbacks of machine learning models for this context. This way, we can implement resources for our kids’ success without perpetuating inequities in our society.